


在 AI 应用开发中,RAG(Retrieval-Augmented Generation,检索增强生成) 已经成为解决大模型两大核心问题的关键技术:
- ❗ 幻觉(Hallucination)
- ⏰ 知识时效性
过去几年里,RAG 几乎形成了一套“标准工程范式”:
文本切片 → 向量化 → 向量数据库 → 语义搜索 → LLM生成
这套流程已经成为开发者的肌肉记忆。
然而最近,OpenAI 在一个法律问答系统案例中展示了一种完全不同的 RAG 思路:
在处理近千页文档时,系统完全没有使用向量数据库。
这个方案几乎可以说是:
“反直觉的 RAG”。
它让很多长期依赖向量检索的开发者产生一个疑问:
如果不用向量检索,模型如何在海量文档中找到答案?
📚 一、RAG 的核心思想

RAG 的本质非常简单:
给大模型提供实时参考资料。
因为大模型本身:
- 不知道你的私有数据
- 不知道最新文件
- 不知道公司知识库
如果直接提问:
模型可能会 胡编乱造(Hallucination)。
因此 RAG 的工作流程是:
用户问题
↓
检索相关文档
↓
将文档 + 问题一起输入模型
↓
模型生成答案
换句话说:
模型不再凭空回答,而是“看着资料回答”。
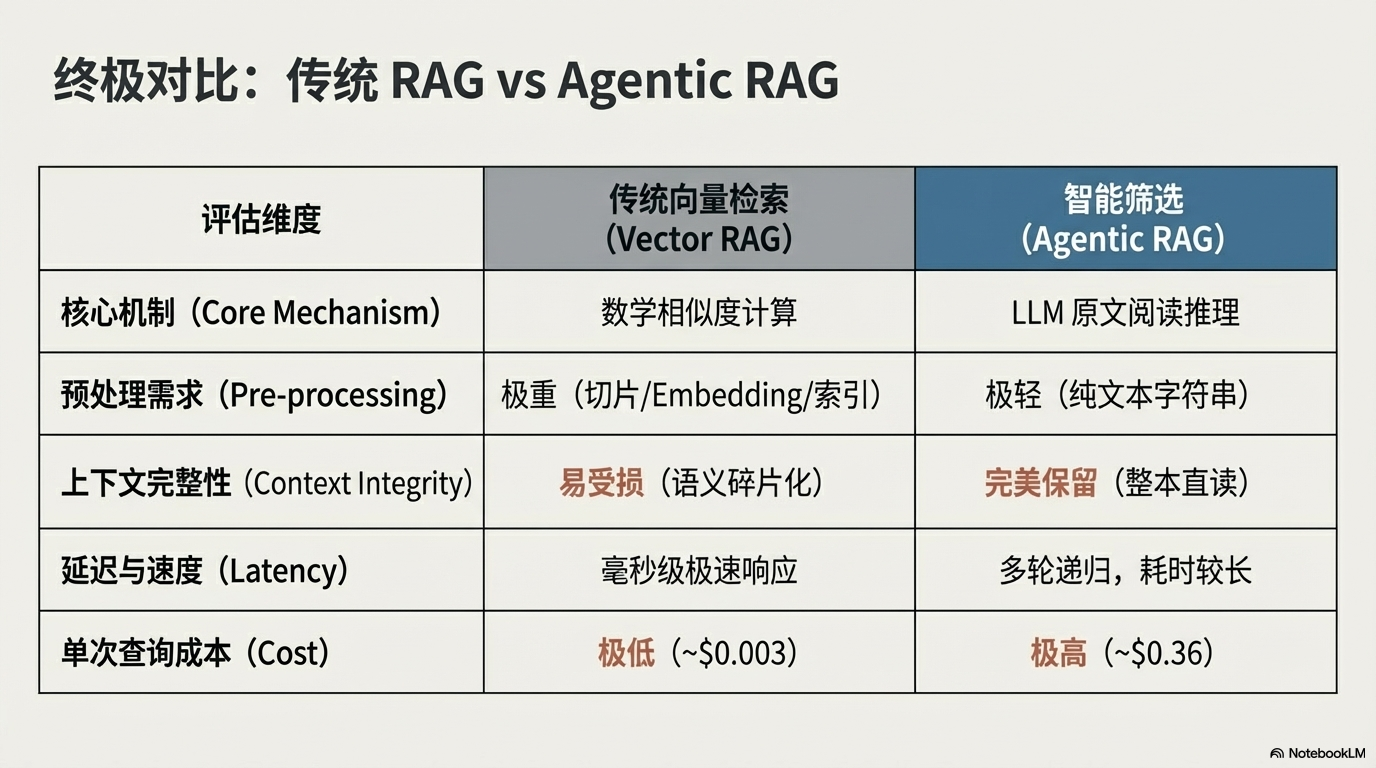
⚙️ 二、传统 RAG:向量检索范式
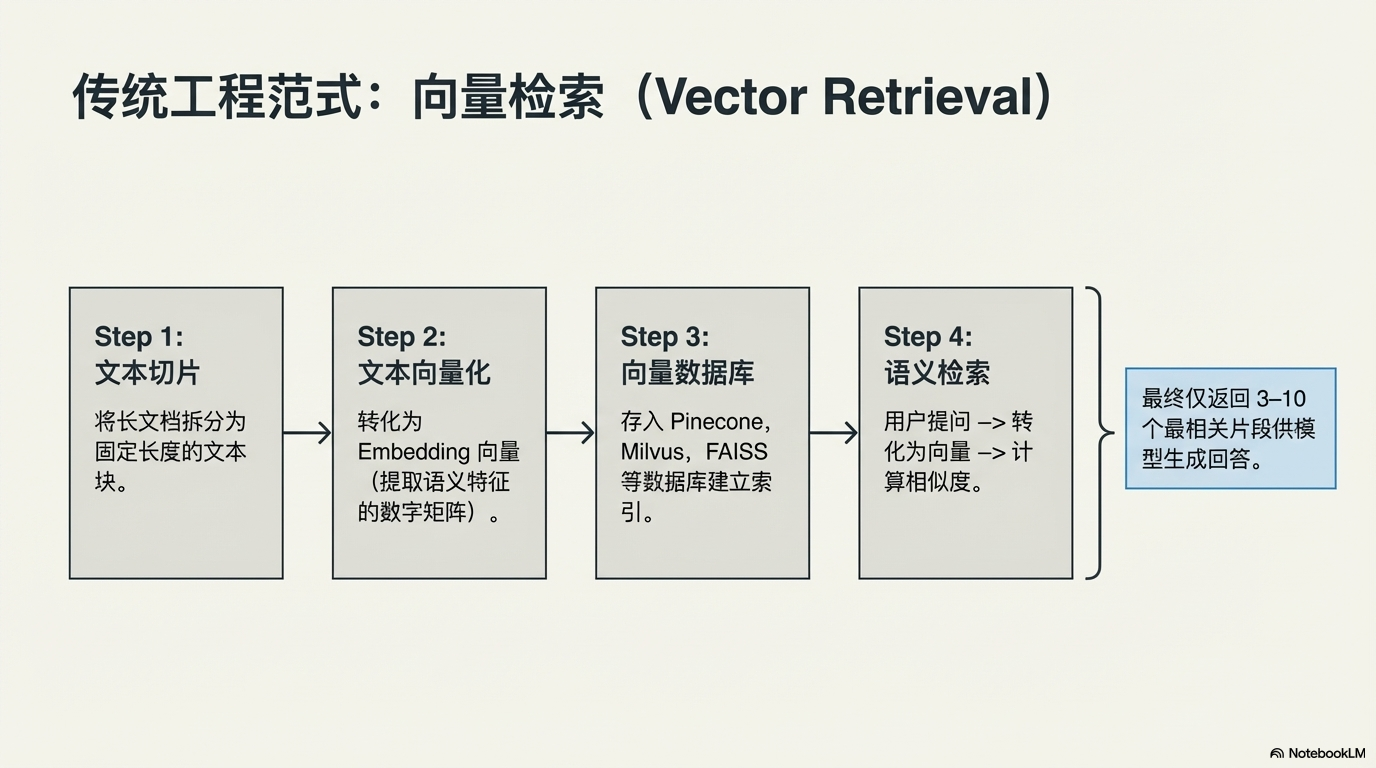
传统 RAG 基本都依赖 向量数据库(Vector Database)。
核心流程如下:
1 文本向量化
首先把文本转换为 Embedding 向量:
"法律条款内容"
↓
[0.21, -0.33, 0.58 ...]
这些数字表示文本的语义特征。
2 建立向量索引
所有文本向量存入数据库:
- Pinecone
- Milvus
- Weaviate
- FAISS
3 语义检索
用户提问:
纽约合同违约赔偿是多少?
系统流程:
问题 → 向量化
↓
向量数据库
↓
相似度搜索
↓
返回最相关文本
通常只返回:
3–10 个最相关片段。
4 生成回答
最后:
相关文本 + 用户问题
↓
LLM生成答案
⚠️ 传统 RAG 的局限
向量检索虽然高效,但存在明显问题:
1 语义碎片化

为了建立索引,文档必须被切碎:
1000页文档
↓
10000个小片段
结果:
上下文被破坏。
2 跨段落信息丢失
很多知识是跨章节的:
条款A
条款B
条款C
向量检索可能只找到 A。
模型因此 理解不完整。
3 复杂预处理
需要大量工程步骤:
- 文档切片
- Embedding
- 索引构建
- 数据同步
💡 三、OpenAI 的新思路:Agentic RAG

OpenAI 在法律问答案例中采用了一种新方法:
Agentic RAG
核心理念是:
让模型自己阅读和筛选文档。
而不是依赖数学向量。
🧠 四、暴力但优雅:直接读取原文
这个方案最大的特点:
完全跳过向量化。
流程变成:
PDF → 纯文本
↓
LLM筛选
↓
递归定位
系统直接把 整本 PDF 转为字符串。

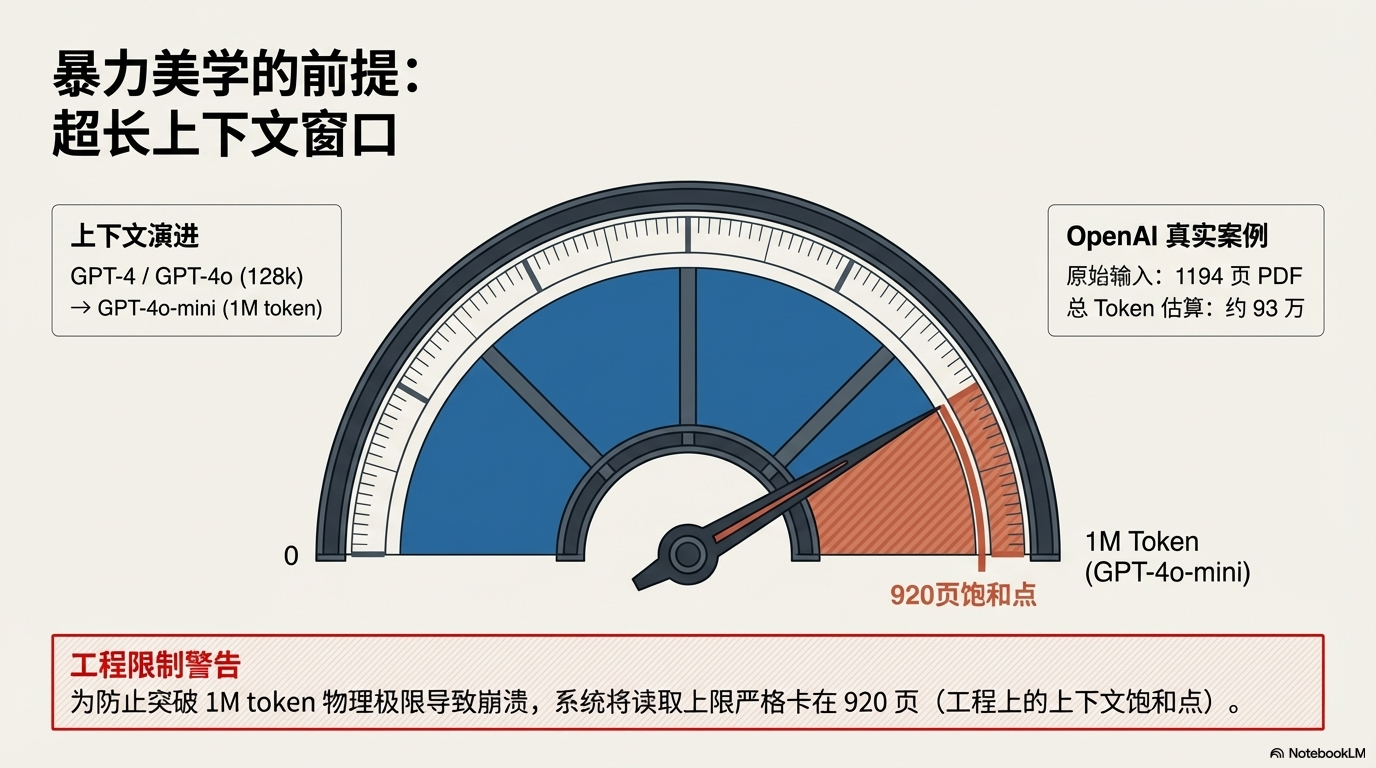
📏 上下文窗口的关键作用
这个方案成立的前提是:
现代模型拥有 超长上下文窗口。
例如:
| 模型 | 上下文 |
|---|---|
| GPT-4 | 128k |
| GPT-4o | 128k |
| GPT-4o-mini | 1M token |
在 OpenAI 案例中:
- 原始 PDF:1194 页
- 总 token:约 93 万
为了不突破 1M token 限制:
系统只读取:
920 页。
这就是工程上的 上下文饱和点。
🔍 五、递归筛选:像人一样查文档
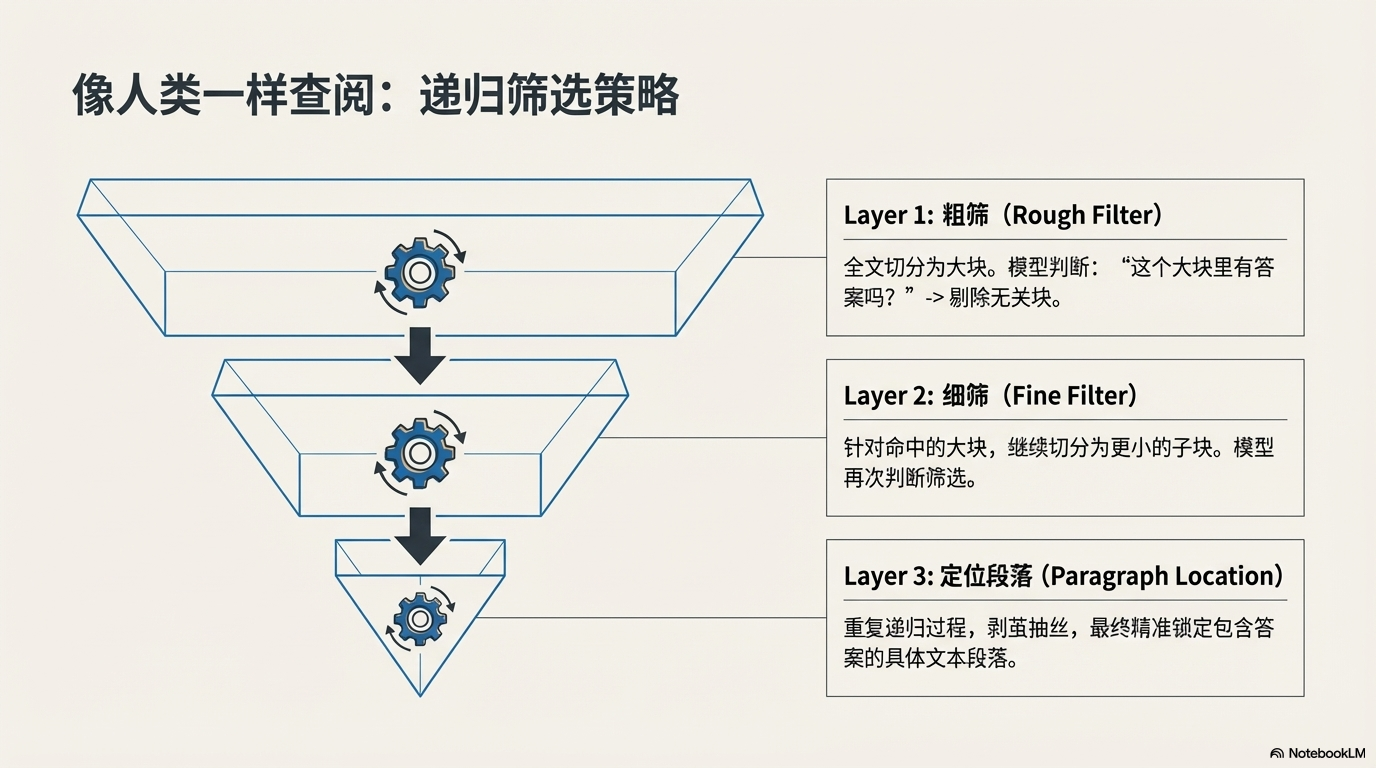
即便有 1M token,也不可能直接读完。
OpenAI 采用了一种 递归筛选策略。
核心逻辑:
split_into_20_chunks
max_depth = 3
流程如下:
第一层:粗筛
全文切成:
20个大块
ID: 0–19
模型判断:
哪些块可能相关?
第二层:细筛
假设选中:
ID 3
ID 14
系统继续:
再切20块
结果:
40个更小块
第三层:定位段落
重复相同过程:
筛选
↓
下钻
↓
定位段落
最终找到具体内容。
🧩 六、Scratchpad:累积思考机制
系统还有一个关键设计:
Scratchpad(思考记录层)
模型每轮筛选必须记录:
- 为什么选这个块
- 当前搜索进度
- 下一步计划
而且这个记录是:
累积的。
Layer1 思考
↓
Layer2 思考
↓
Layer3 思考
因此模型不会在深层递归中:
迷失方向。
🤖 七、三模型协作架构
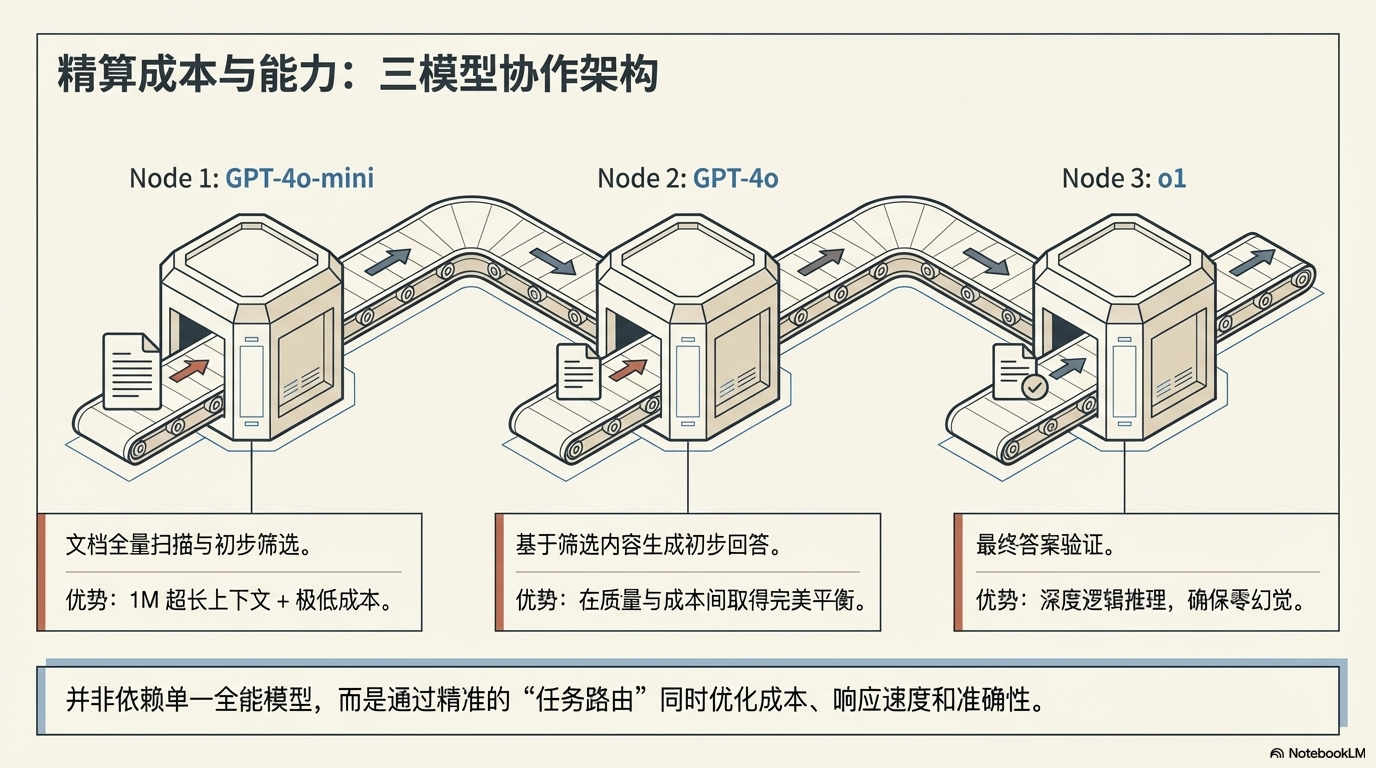
OpenAI 并没有使用单一模型。
而是采用 分工架构:
| 环节 | 模型 | 作用 |
|---|---|---|
| 文档扫描 | GPT-4o-mini | 超长上下文 + 低成本 |
| 初步回答 | GPT-4o | 平衡质量与成本 |
| 最终验证 | o1 | 深度逻辑推理 |
架构如下:
User
↓
GPT-4o-mini(筛选)
↓
GPT-4o(生成)
↓
o1(验证)
这种方式:
同时优化成本、质量和准确性。
💰 八、现实问题:它很强,但也很贵

这种 Agentic RAG 非常优雅。
但也存在现实成本。
成本
单次查询成本:
约 $0.36
相比向量检索:
贵 100 倍。
延迟
由于涉及:
- 多轮递归
- 多次模型调用
响应时间:
明显更慢。
上下文限制
当文档规模达到:
数千页
即使 1M token 也不够。
必须引入:
横向切分策略。
🔮 九、未来:向量数据库会消失吗?
答案很可能是:
不会。
未来更可能的架构是:
海量数据
↓
向量检索(初筛)
↓
Agentic RAG(深度定位)
↓
LLM生成
也就是说:
数学检索 + 语义理解
将长期共存。

🧾 结语
OpenAI 的这一实验性架构表明:
当模型理解能力和上下文窗口足够强大时,
复杂的数学检索可能只是过渡方案。
未来的 AI 系统,可能不再只是数据库查询系统,而是:
真正能够阅读和理解知识的“数字大脑”。
当推理成本持续下降、上下文窗口趋近无限时,一个更深刻的问题将浮现:
我们是在构建数据库,
还是在构建一个能够读懂世界的 AI?
评论区