


在 AI 大模型爆发的时代,很多企业都希望构建一个:
真正懂自家产品的 AI 知识助手
例如:
- 智能客服
- 企业知识库
- 技术支持机器人
但很快大家会发现一个问题:
像 GPT-4 这样的通用大模型,并不了解公司的内部资料。
如果你直接把 几百页甚至几千页文档“喂”给模型,往往会出现三个问题:
⚠️ 上下文窗口限制
⚠️ 推理成本过高
⚠️ 回答容易产生幻觉
为了解决这些问题,一种关键技术出现了:
RAG(Retrieval-Augmented Generation)
🧠 一、什么是 RAG?
RAG 的核心逻辑其实非常简单:
先检索
再生成
具体流程是:
用户问题
↓
检索相关资料
↓
把资料交给大模型
↓
生成答案
也就是说:
AI 不再凭记忆回答,而是先查资料再回答。
这就像一个专业顾问在回答问题前,会先翻阅公司的内部手册。
⚠️ 二、为什么不能直接把文档喂给 AI?
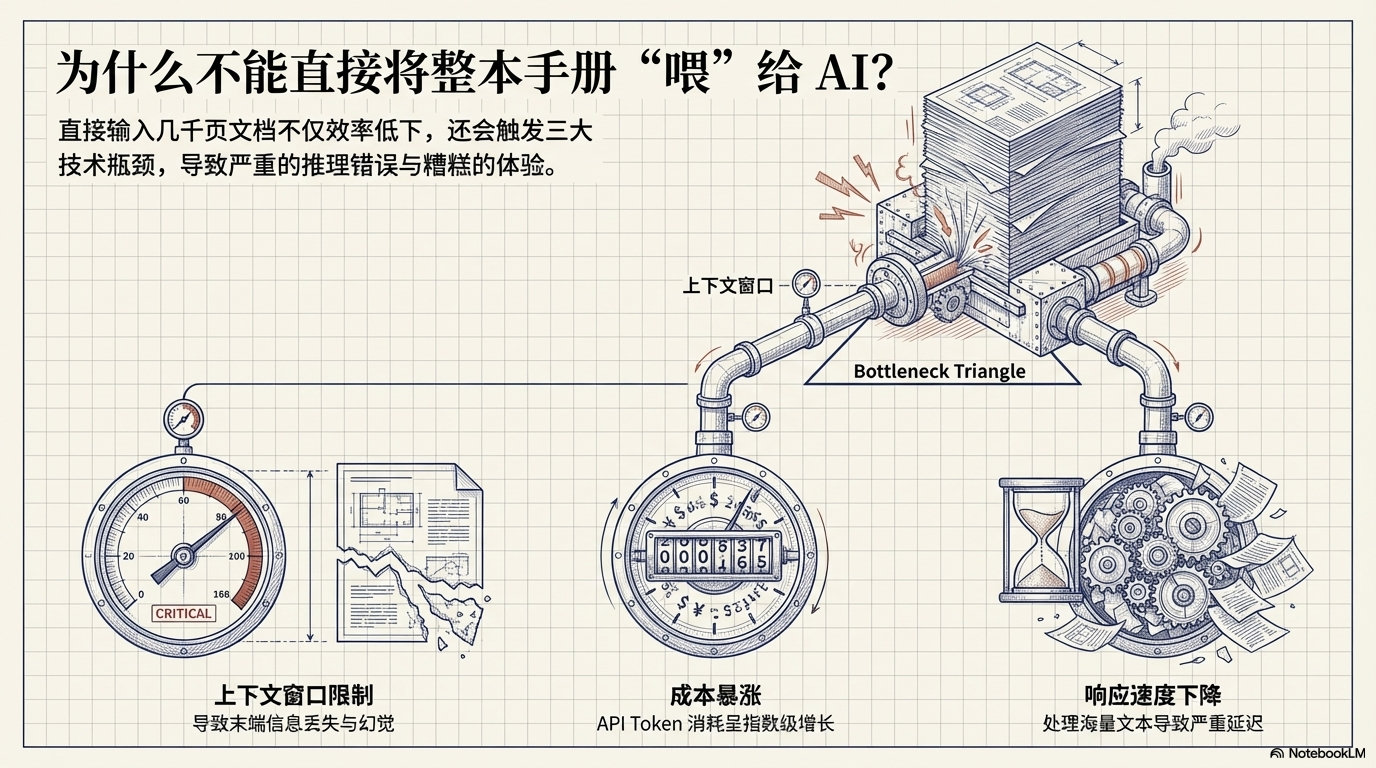
很多人最初都会尝试:
把整个产品手册上传给 AI
但这样做会遇到三个技术瓶颈。
1️⃣ 上下文窗口限制
每个模型都有 Context Window(上下文窗口)。
例如:
- 一些模型只能处理几万 Token
- 文档往往远远超过这个长度
当输入太长时:
模型读到后面
忘记前面
导致回答错误。
2️⃣ 成本暴涨
在 API 计费模型中:
Token = 钱
如果每次提问都附带整本手册:
成本会 指数级增长。
3️⃣ 响应速度下降
处理大量文本会导致:
- 推理时间变长
- 用户体验变差
⚙️ 三、RAG 的核心流程(五个步骤)
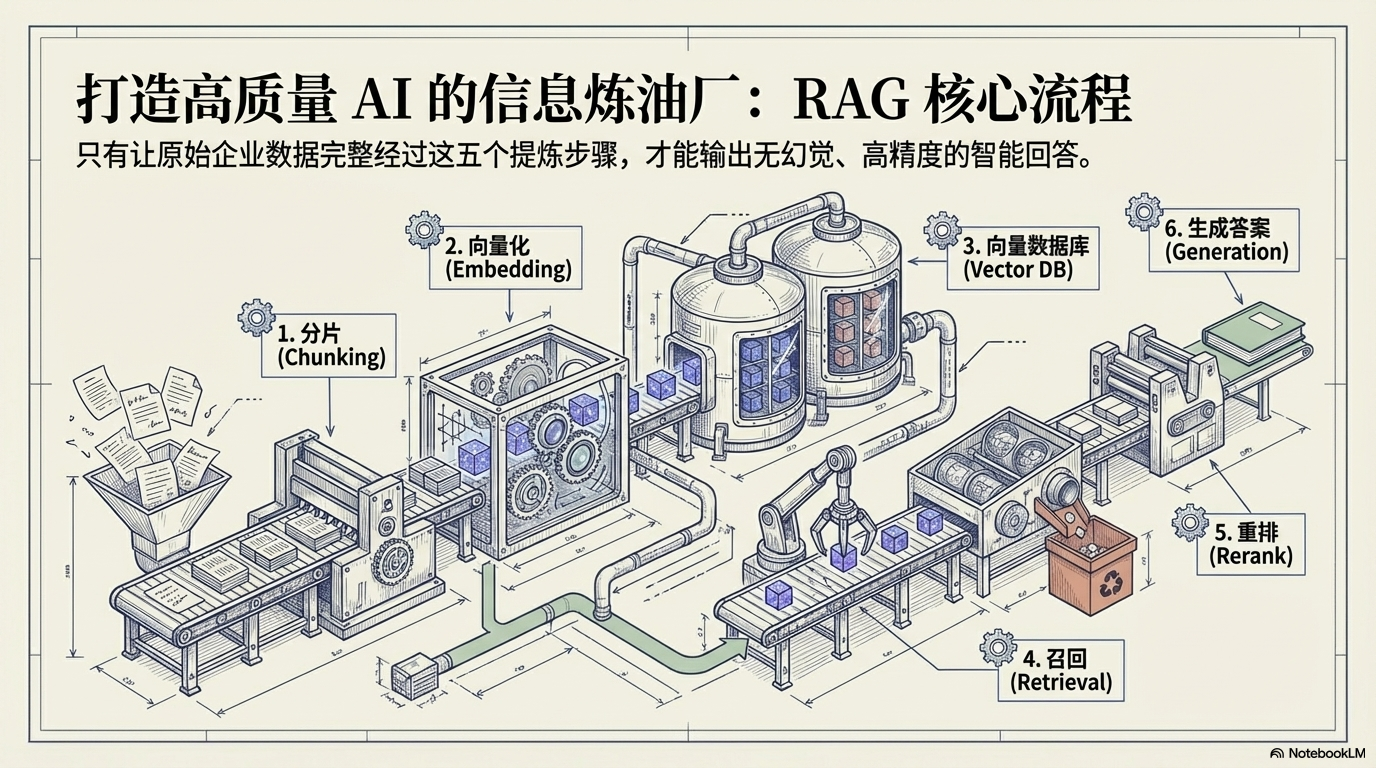
一个完整的 RAG 系统通常包含 五个关键步骤:
分片
↓
索引
↓
召回
↓
重排
↓
生成
我们逐个来看。
📦 四、步骤一:分片(Chunking)
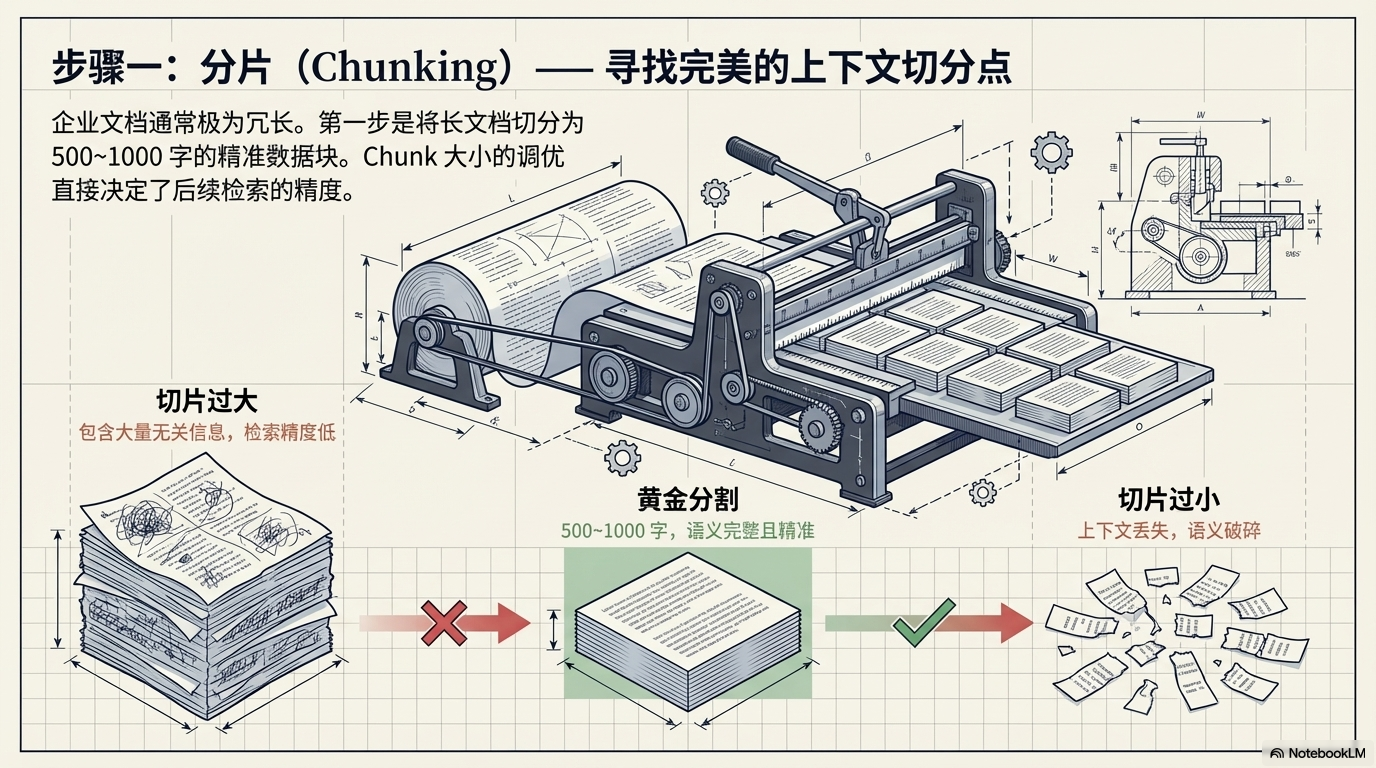
企业文档通常非常长。
因此第一步是:
把文档切成小块。
例如:
- 每 500~1000 字一段
- 按自然段切割
- 按章节切割
示例:
原始文档
↓
Chunk1
Chunk2
Chunk3
分片的核心目的:
提高检索精度。
如果片段太大:
- 会包含大量无关信息
如果片段太小:
- 语义可能不完整
所以 Chunk 大小需要调优。
🧮 五、步骤二:Embedding(向量化)
切好的文本需要转换成 向量(Vector)。
这个过程叫:
Embedding
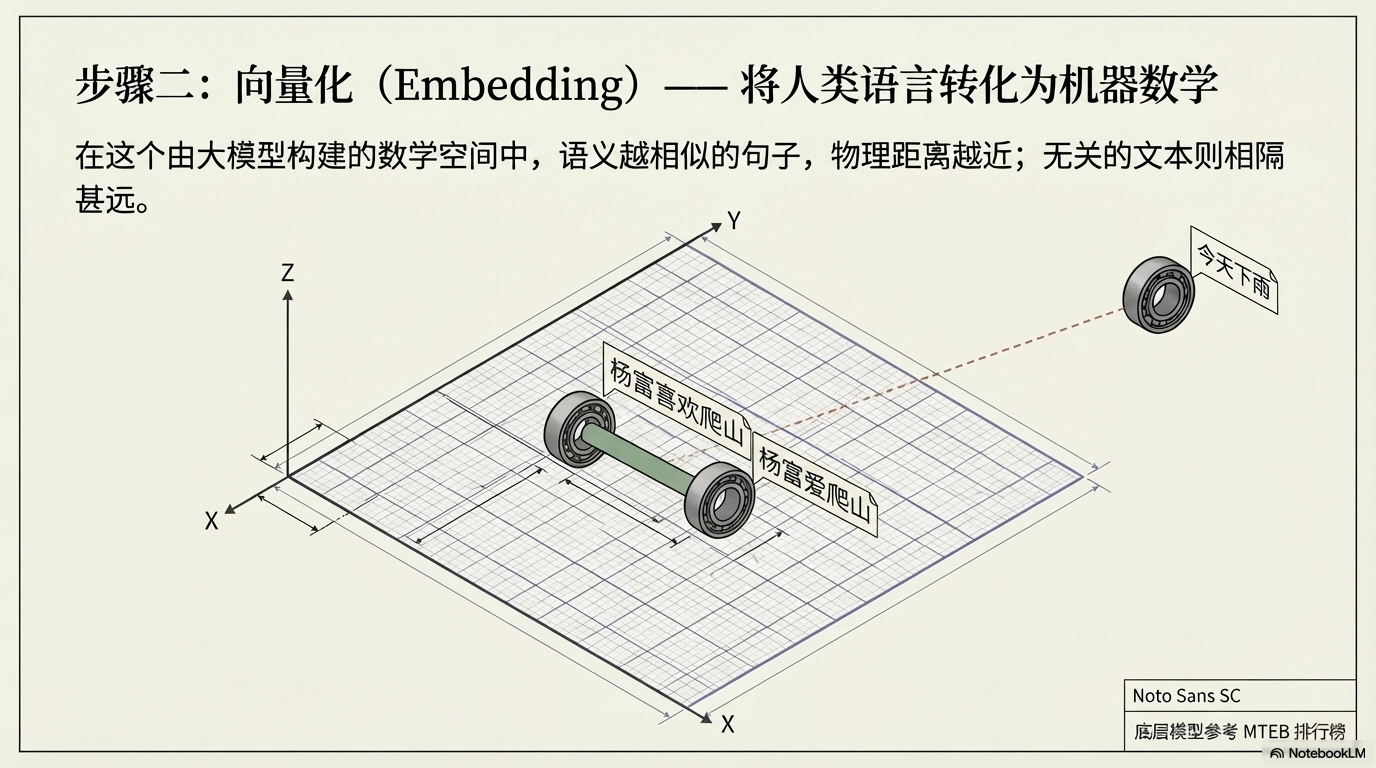
Embedding 模型会把一段文字转换成一个高维向量,例如:
[0.13, -0.82, 0.54, ...]
在这个数学空间中:
- 语义相似的文本距离更近
- 无关文本距离更远
例如:
| 文本 | 向量距离 |
|---|---|
| 杨富喜欢爬山 | 接近 |
| 杨富爱爬山 | 非常接近 |
| 今天下雨 | 很远 |
常见 Embedding 模型通常会参考:
MTEB
这个排行榜可以帮助选择最好的向量模型。
🗄 六、步骤三:向量数据库
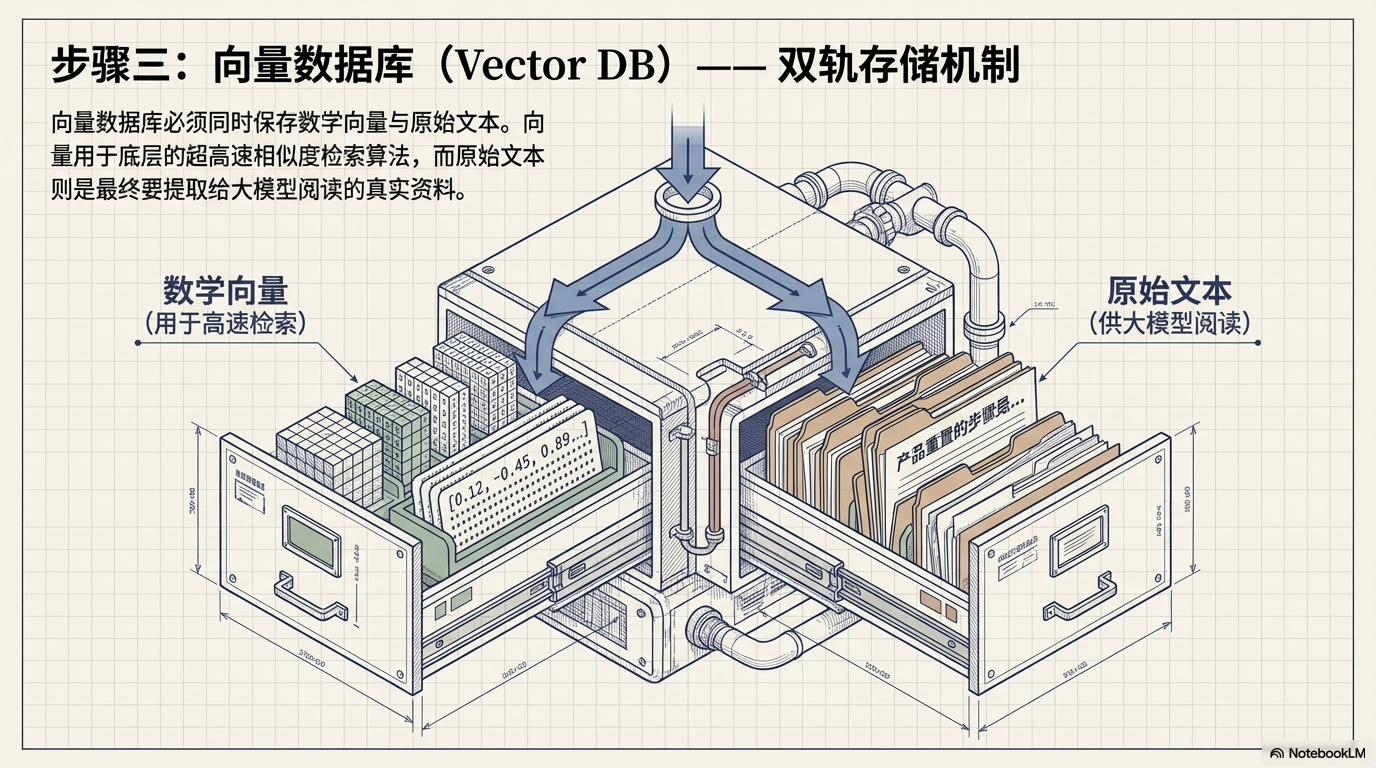
生成向量后,需要存入 向量数据库。
数据库通常包含两列:
| 向量 | 原始文本 |
|---|---|
| embedding vector | chunk 内容 |
这里有一个关键点:
⚠️ 必须保存原始文本
因为:
- 向量用于计算相似度
- 文本才是最终给 AI 阅读的内容
🔍 七、步骤四:召回(Retrieval)
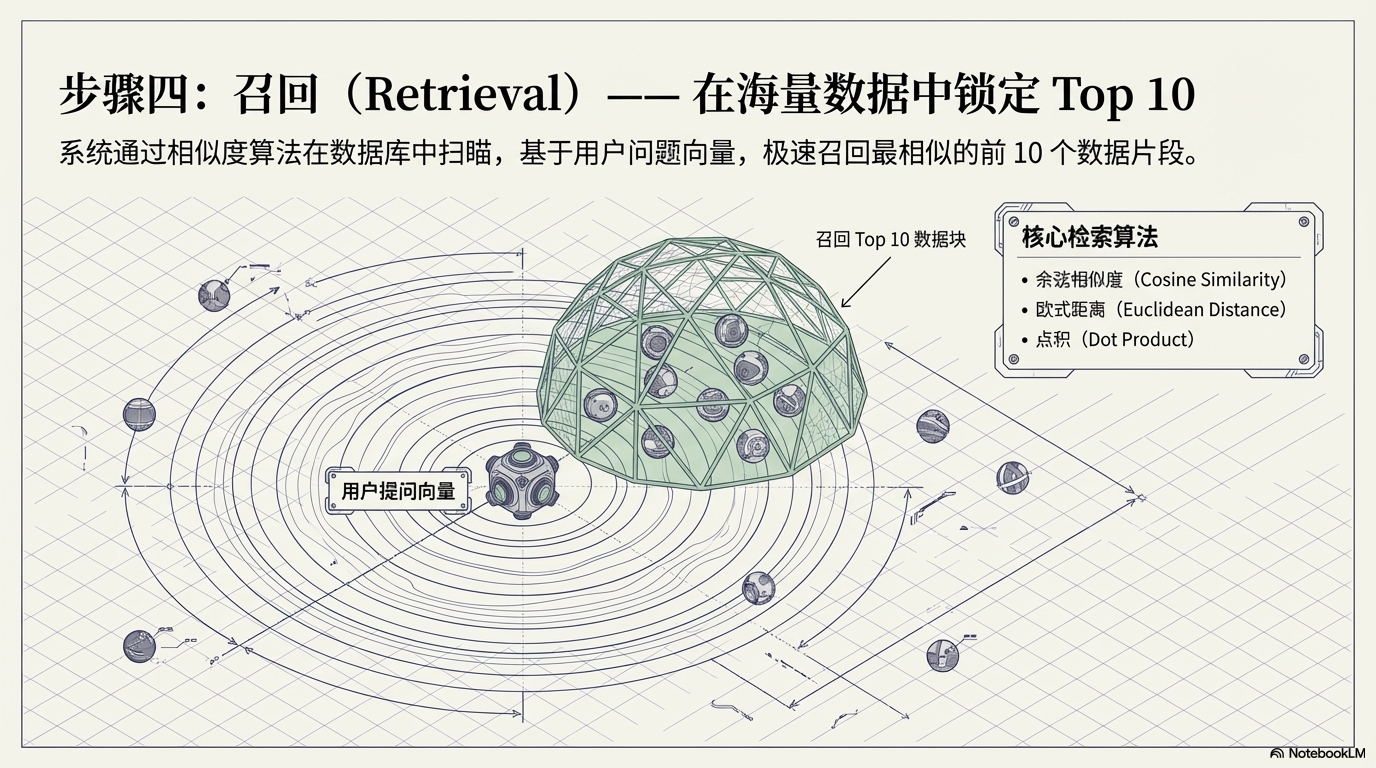
当用户提出问题时:
系统会执行:
问题 → 向量化
然后在数据库中找到:
最相似的片段
通常取:
Top 10
常见相似度算法包括:
- 余弦相似度(Cosine Similarity)
- 欧式距离(Euclidean Distance)
- 点积(Dot Product)
召回阶段的特点:
速度快
成本低
但精度一般
所以需要下一步。
🎯 八、步骤五:重排(Rerank)
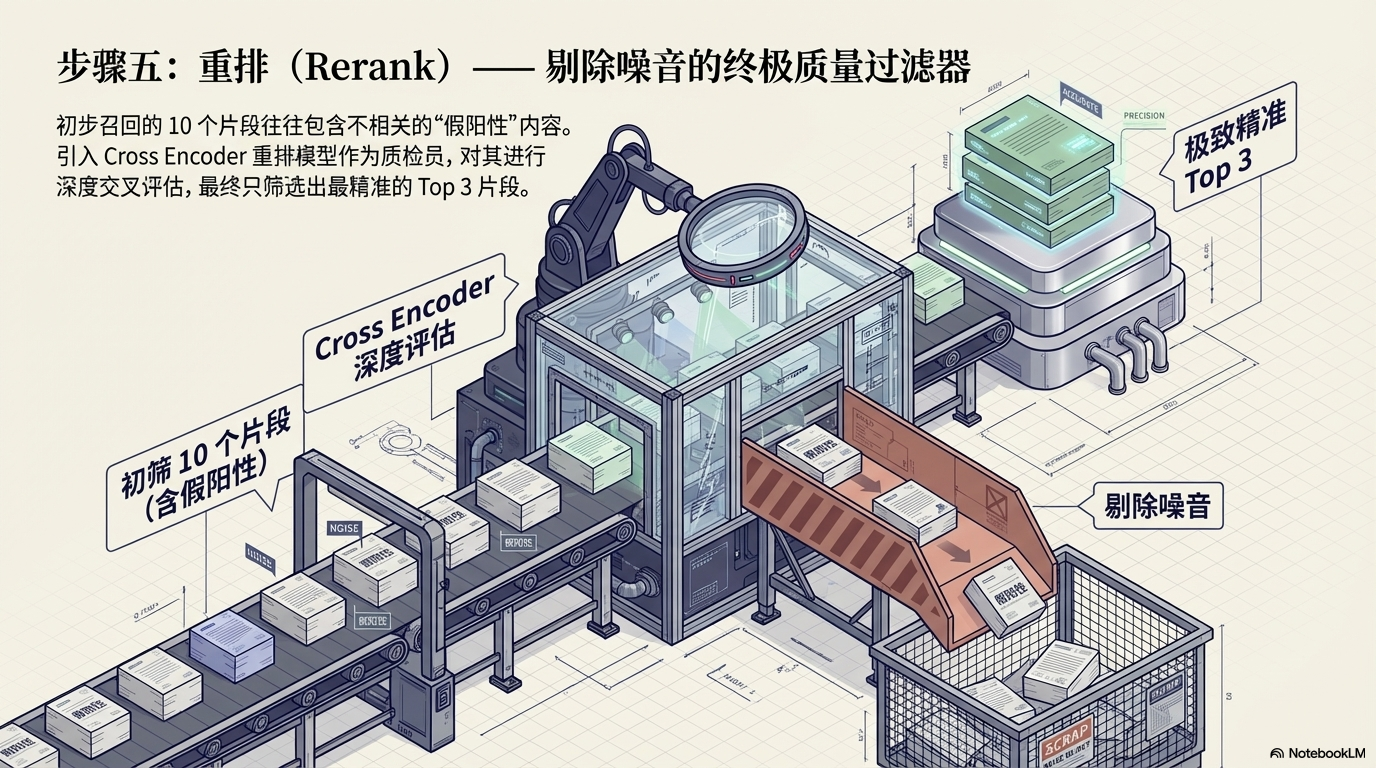
召回得到的 10 个片段中:
有些相关
有些不太相关
因此需要:
Rerank 模型
通常使用:
Cross Encoder
它会:
问题 + 文本
↓
深度语义匹配
最终选出:
Top 3
可以用一个经典类比理解:
召回 = 简历筛选
重排 = 面试
🤖 九、最后一步:生成答案
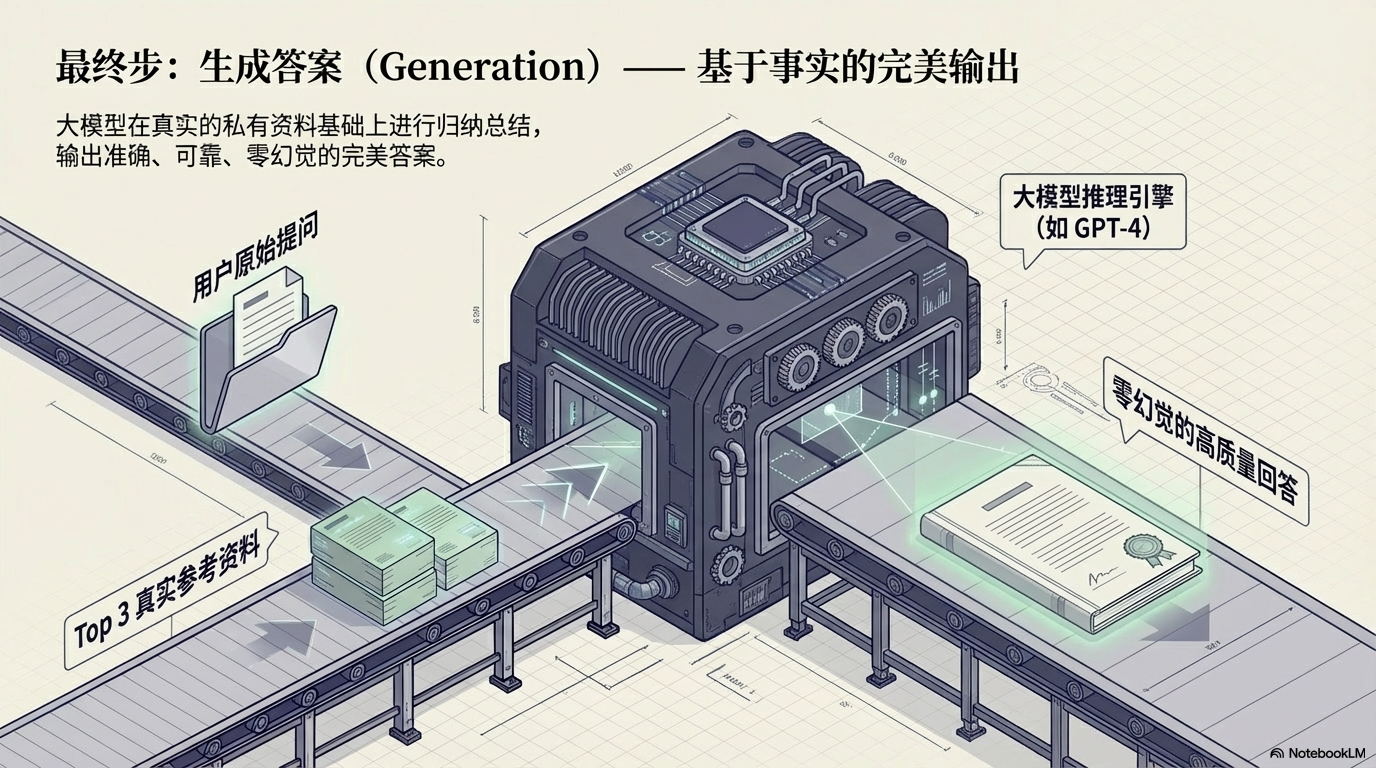
最后系统会把:
用户问题
+
Top3 文档
一起发送给大模型,例如 GPT-4。
模型在这些真实资料的基础上生成答案。
因此回答会:
✅ 更准确
✅ 更可靠
✅ 几乎没有幻觉
🧩 十、完整 RAG 架构
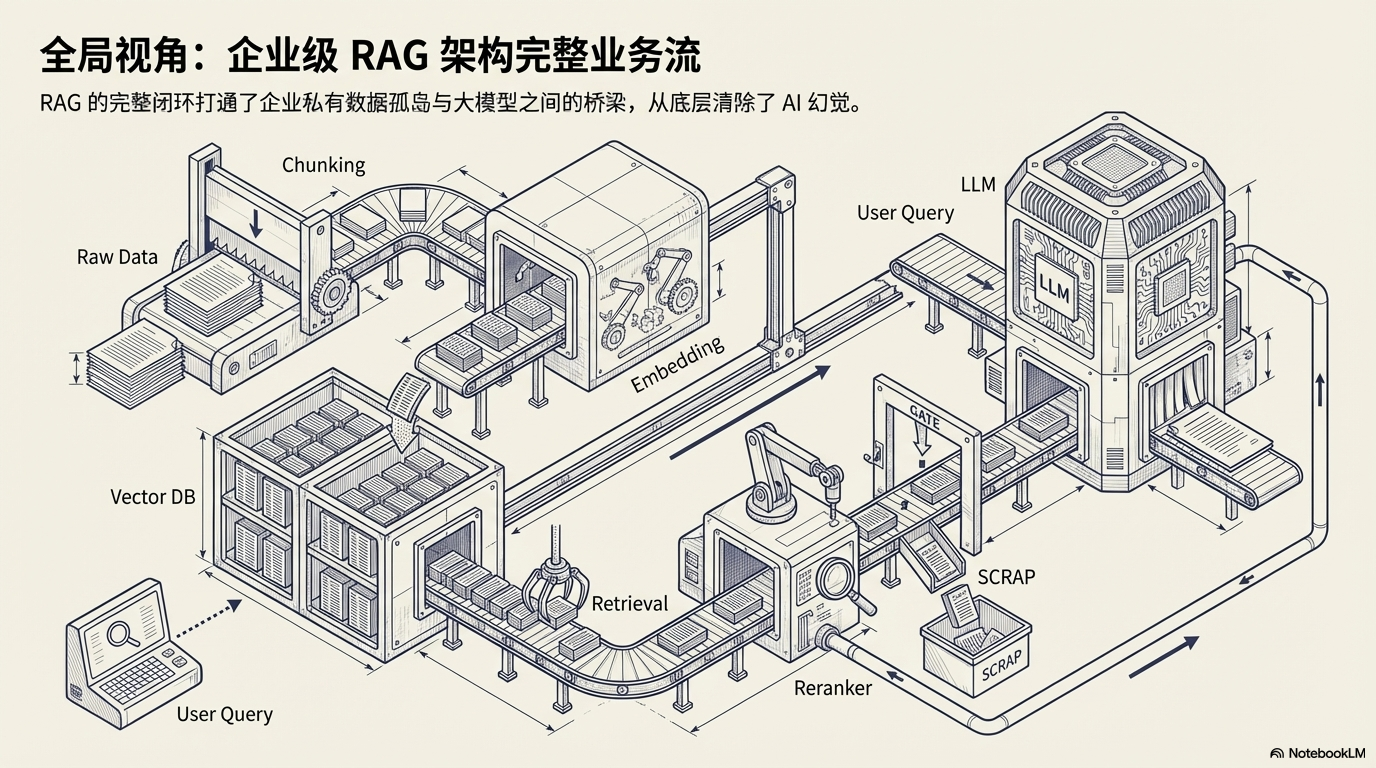
整个系统可以用一张结构图理解:
数据准备阶段
文档
↓
Chunking
↓
Embedding
↓
Vector Database
查询阶段
用户问题
↓
Embedding
↓
Vector Search
↓
Rerank
↓
LLM
↓
最终回答
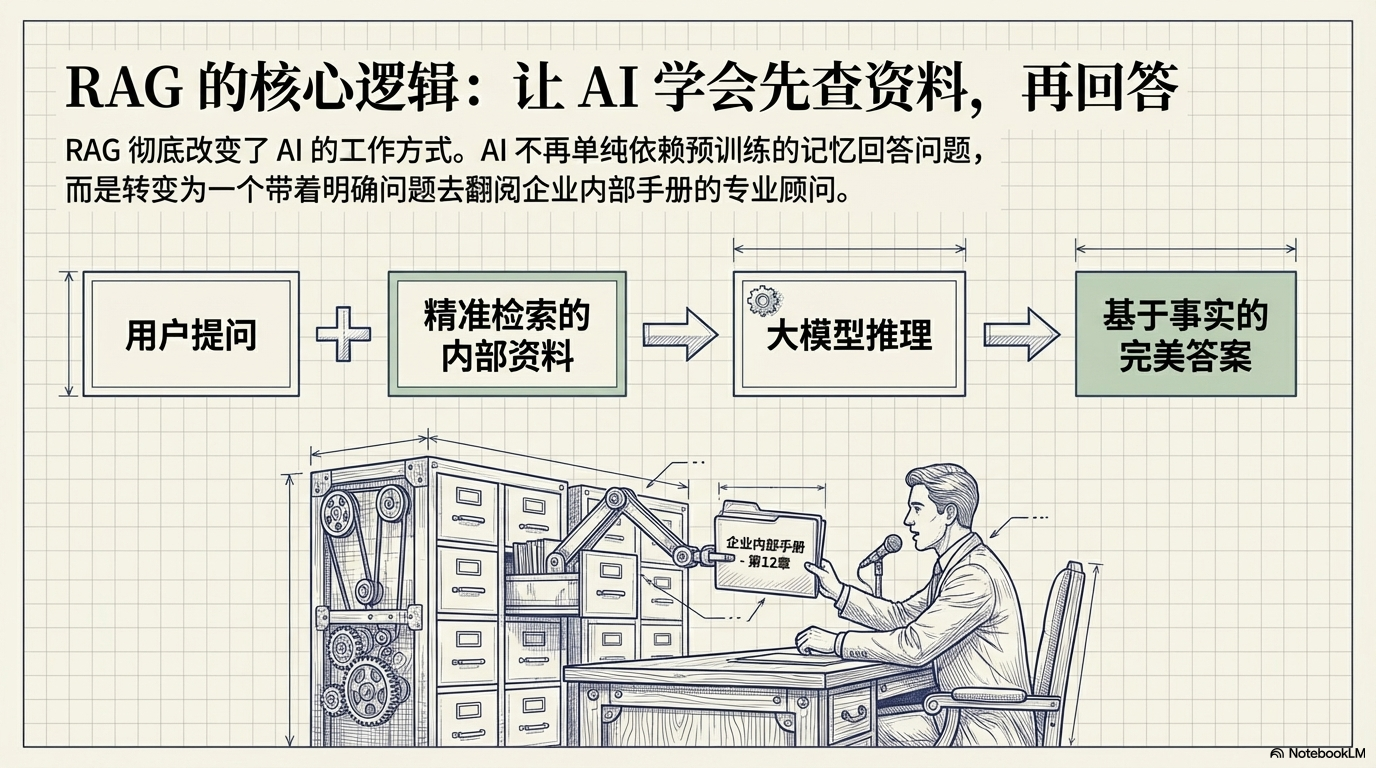
🚀 总结

RAG 的核心价值在于:
让 AI 学会“查资料再回答”。
通过 分片 → 向量化 → 检索 → 重排 → 生成 这五个步骤,
RAG 可以解决大模型的两个关键问题:
- 私有知识缺失
- 幻觉问题
因此在企业 AI 落地中:
RAG 已经成为 最核心的技术架构之一。
📌 最后留一个值得思考的问题:
如果未来每家公司都拥有:
自己的向量数据库
+
自己的AI知识助手
那么真正的竞争优势,
或许不再是模型本身,
而是:
谁拥有最优质的知识库。
评论区