


前言
在当前人工智能技术浪潮中,大型语言模型(LLM)已成为驱动创新和重塑行业格局的核心力量。它们在理解、生成和处理复杂信息方面的能力,正以前所未有的速度拓展着人机交互的边界。随着各科技巨头和领先研究机构不断推出迭代更新的模型,对其综合性能进行系统性评估和比较,对于技术选型、应用开发乃至未来研究方向的判断都至关重要。
本报告旨在对当前业界具有代表性的前沿大型语言模型进行深度分析与比较,其中包括 OpenAI 的 GPT 系列、Google 的 Gemini 系列、Anthropic 的 Claude 系列以及 DeepSeek 的最新成果。我们将聚焦于模型的关键性能维度,如推理逻辑、编程能力、数学问题解决、数据分析等核心智力指标,并特别关注其在处理复杂任务中至关重要的上下文长度表现。
通过对这些模型在各项基准测试中的量化数据进行细致考察,我们将揭示不同模型的设计哲学与性能侧重点,探究它们在应对不同应用场景时的潜在优势与局限。此次对比分析旨在为专业人士和技术爱好者提供一个清晰、客观的视角,以理解当前 LLM 领域的最新进展及其对未来技术生态的深远影响。
性能对比表
能力柱状对比图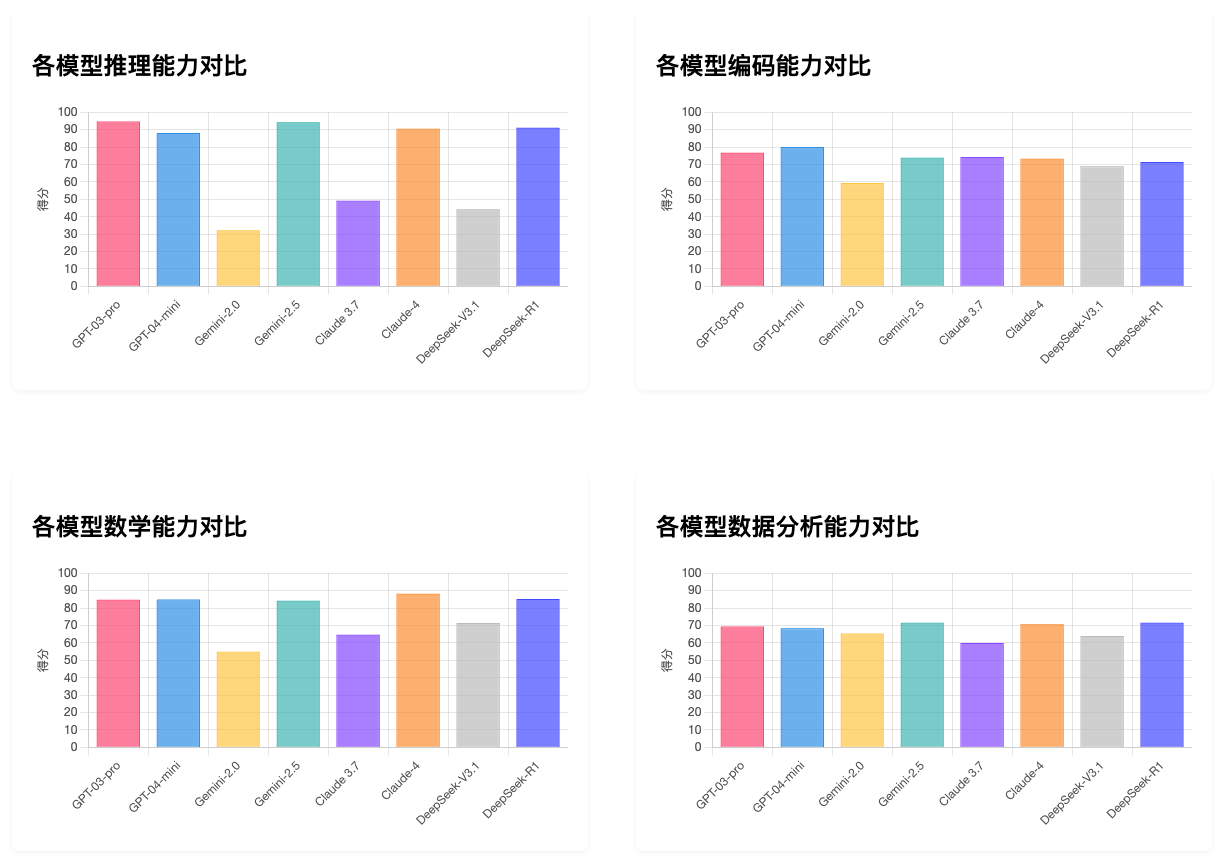
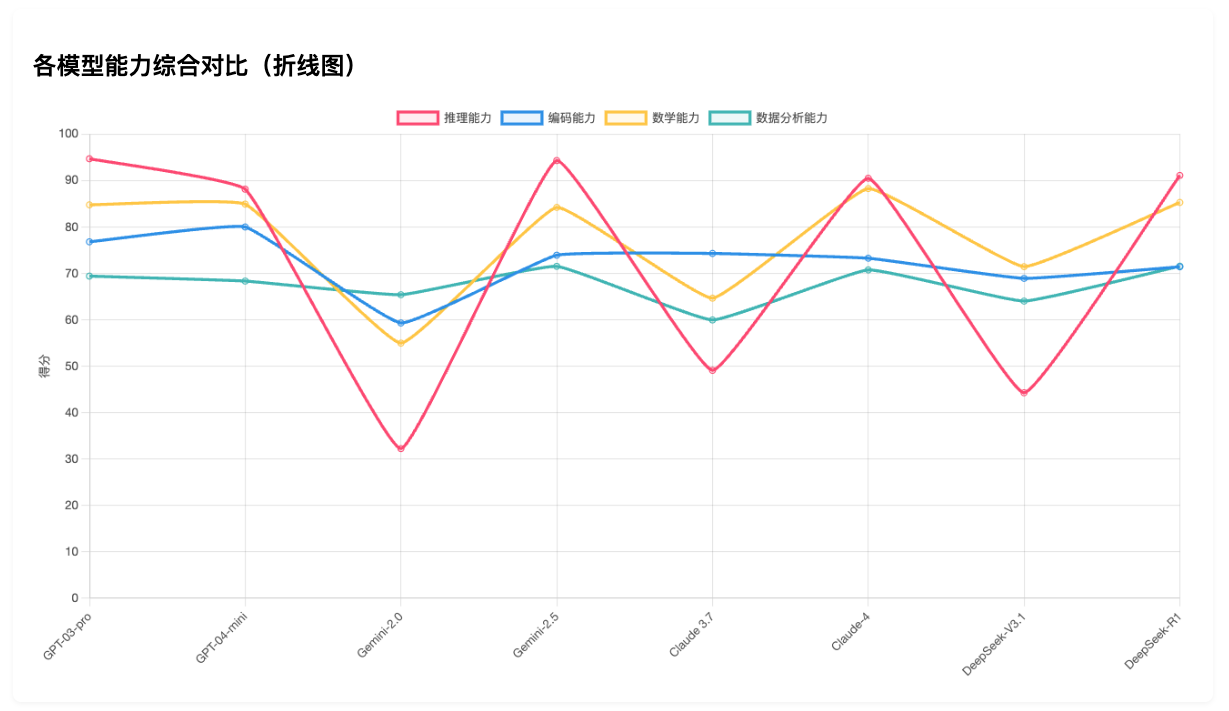
能力折线对比图
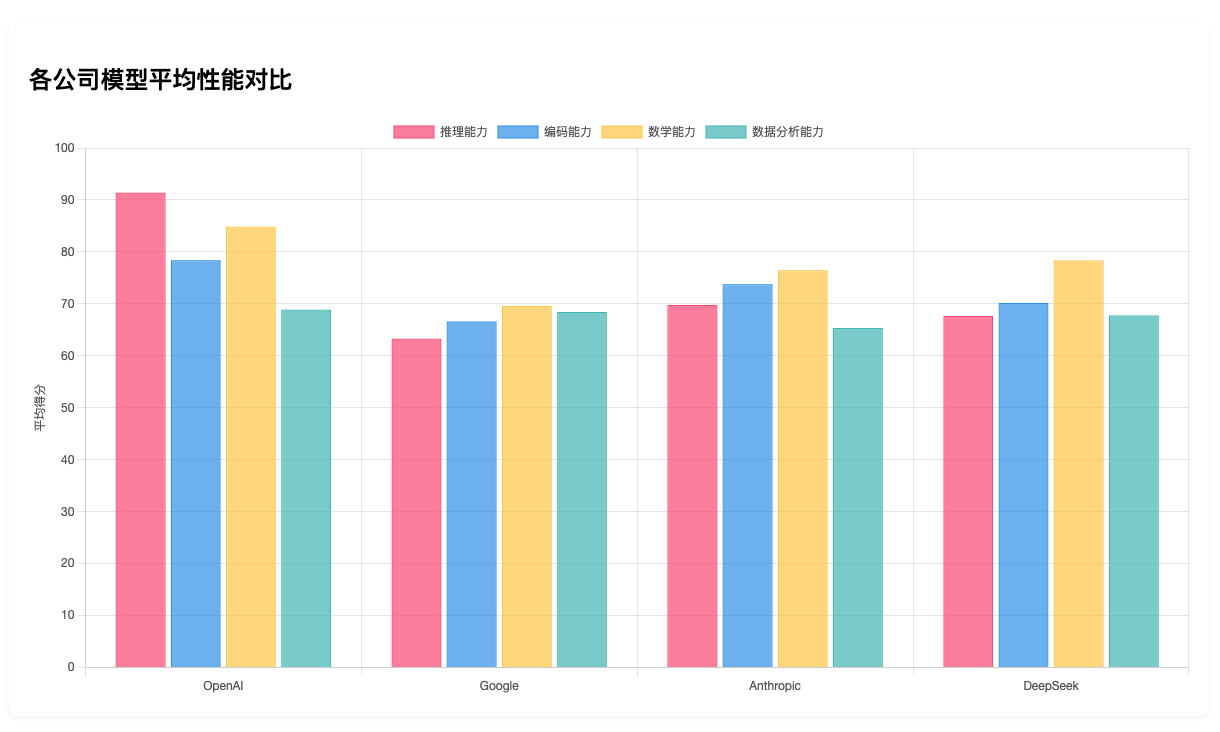
公司柱状对比图
备注
Claude Opus 的 MMLU 为 Anthropic 提供的 MMMLU 分数,非标准 MMLU。
OpenAI 模型未公开标准测试分数,但声称在多个基准上达到最优水平。
参考资料
OpenAI 官方新闻稿openai.comopenai.com
Google DeepMind 官方博客blog.googleblog.googledevelopers.googleblog.com
Anthropic 官方公告anthropic.comanthropic.comanthropic.com
DeepSeek 技术报告与 GitHub
评论区